

Autores
DLL hijacking é uma técnica comum em que atacantes substituem uma biblioteca carregada por um processo legítimo por uma versão maliciosa. Ela é usada por criadores de malware de impacto em massa, como stealers e trojans bancários (cavalos de Troia), e por APT e grupos de crimes cibernéticos que estão por trás de ataques direcionados. Nos últimos anos, o número de ataques de DLL hijacking cresceu de forma significativa.
Tendência no número de ataques de DLL hijacking. Os dados de 2023 são considerados como 100% (download)
Observamos essa técnica e suas variações, como DLL sideloading, em ataques direcionados a organizações na Rússia, África, Coreia do Sul e em outros países e regiões. Lumma, um dos stealers mais ativos de 2025, utiliza esse método para distribuição. Threat actors tentando lucrar com aplicativos populares, como o DeepSeek, também recorrem ao DLL hijacking.
Não é fácil detectar um ataque de substituição de DLL, porque a biblioteca é executada dentro do espaço de endereço confiável de um processo legítimo. Portanto, para uma solução de segurança, essa atividade pode parecer um processo confiável. Dedicar atenção excessiva a processos confiáveis pode comprometer o desempenho geral do sistema. Portanto, é necessário encontrar o equilíbrio entre um nível suficiente de segurança e um nível adequado de conveniência, o que pode ser delicado.
Detecção de DLL hijacking com um modelo de machine learning
A inteligência artificial pode ajudar onde algoritmos de detecção simples são insuficientes. A Kaspersky utiliza machine learning há 20 anos para identificar atividades maliciosas em diferentes estágios. O centro de especialização de IA pesquisa as capacidades de diferentes modelos na detecção de ameaças, depois os treina e implementa. Nossos colegas do centro de inteligência em ameaças nos trouxeram as seguintes questões: se é possível utilizar machine learning para detectar DLL hijacking e, mais importante, se isso poderia aprimorar a precisão da detecção.
Preparação
Para determinar se poderíamos treinar um modelo para distinguir entre carregamentos de bibliotecas maliciosos e legítimos, primeiro era necessário definir um conjunto de características que indicassem com precisão um DLL hijacking. Identificamos as seguintes características principais:
- Localização incorreta da biblioteca. Muitas bibliotecas padrão localizam-se em diretórios padrão, enquanto uma DLL maliciosa é frequentemente encontrada em um local incomum, como na mesma pasta que o arquivo executável que a carrega.
- Local incorreto do arquivo executável. Os atacantes quase sempre salvam os arquivos executáveis em caminhos não padrão, como diretórios temporários ou pastas de usuários, em vez de salvá-los nos %Arquivos de programas%.
- Arquivo executável renomeado. Para evitar a detecção, os atacantes frequentemente salvam aplicativos legítimos com nomes arbitrários.
- O tamanho da biblioteca foi alterado e não está mais assinado.
- Estrutura da biblioteca modificada.
Amostra de treinamento e rotulagem
Para a amostra de treinamento, utilizamos dados de carregamento de bibliotecas dinâmicas fornecidos por nossos sistemas internos de processamento automático, que lidam com milhões de arquivos diariamente, além de telemetria anonimizada, como a fornecida voluntariamente pelos usuários da Kaspersky por meio da Kaspersky Security Network.
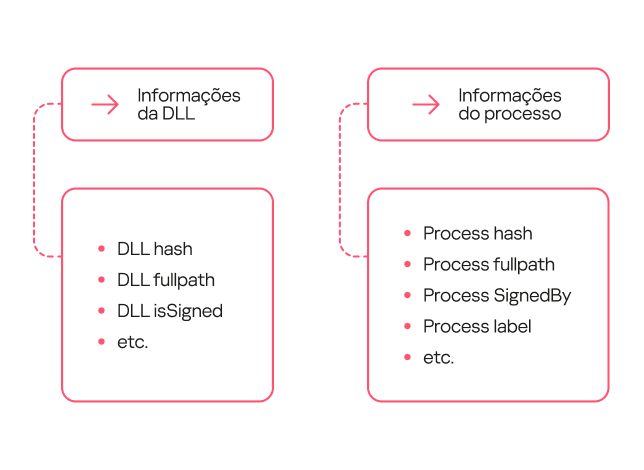
A amostra de treinamento foi rotulada em três iterações. Inicialmente, os analistas não puderam extrair automaticamente a rotulagem de eventos que indicavam se um evento era considerado um ataque de DLL hijacking. Portanto, utilizamos dados de nossos bancos de dados que continham apenas informações de reputação de arquivos. O restante dos dados foi rotulado de forma manual. Rotulamos como DLL hijacking aqueles eventos de carregamento de biblioteca em que o processo era definitivamente legítimo, mas a DLL era definitivamente maliciosa. No entanto, essa rotulagem não foi suficiente, porque alguns processos, como o “svchost”, têm como principal função carregar diversas bibliotecas. Como resultado, o modelo que treinamos com esses dados teve uma taxa de falsos positivos alta e não era prático para uso no mundo real.
Na próxima iteração, filtramos também as bibliotecas maliciosas por família, mantendo apenas aquelas que eram conhecidas por exibirem comportamento de DLL hijacking. O modelo treinado com esses dados refinados mostrou uma precisão muito melhor e essencialmente confirmou nossa hipótese de que era possível usar machine learning para detectar esse tipo de ataque.
Nesse estágio, nosso conjunto de dados de treinamento tinha dezenas de milhões de objetos. Ele incluía cerca de 20 milhões de arquivos limpos e quase 50 mil arquivos definitivamente maliciosos.
| Status | Total | Arquivos exclusivos |
| Desconhecidos | aprox. 18 milhões | aprox. 6 milhões |
| Maliciosos | aprox. 50 mil | aprox. 1.000 |
| Limpos | aprox. 20 milhões | aprox. 250 mil |
Em seguida, treinamos modelos subsequentes com base nos resultados de seus predecessores, que foram verificados e posteriormente rotulados por analistas. Esse processo aumentou muito a eficiência do nosso treinamento.
Carregamento de DLLs: o que é considerado normal?
Tivemos uma amostra rotulada com um grande número de eventos de carregamento de biblioteca de vários processos. Como podemos descrever uma biblioteca “limpa”? Usar uma combinação de nome de processo + nome de biblioteca não considera processos que foram renomeados. Além disso, um usuário legítimo, não apenas um atacante, pode renomear um processo. Se usássemos o hash do processo em vez do nome, resolveríamos o problema de renomeação, mas então, cada versão da mesma biblioteca seria tratada como uma biblioteca separada. Por fim, decidimos usar uma combinação de nome de biblioteca + assinatura de processo. Embora essa abordagem considere todas as bibliotecas com nomes idênticos de um único fornecedor como sendo uma só, ela geralmente produz um cenário mais ou menos realista.
Para descrever eventos de carregamento seguro de uma biblioteca, usamos um conjunto de contadores que incluíam informações sobre os processos (a frequência de um nome de processo específico para um arquivo com um determinado hash, a frequência de um caminho de arquivo específico para um arquivo com esse hash e assim por diante), informações sobre as bibliotecas (a frequência de um caminho específico para aquela biblioteca, a porcentagem de ativações legítimas e assim por diante) e propriedades do evento (ou seja, se a biblioteca está no mesmo diretório que o arquivo que a carrega).
O resultado foi um sistema com diversos agregados (conjuntos de contadores e chaves) que podiam descrever um evento de entrada. Esses agregados podem conter uma única chave (por exemplo, a hash sum de uma DLL) ou várias chaves (por exemplo, a hash sum de um processo + a assinatura do processo). Com base nesses agregados, é possível derivar um conjunto de características que descrevem o evento de carregamento da biblioteca. O diagrama abaixo fornece exemplos de como essas características são derivadas:
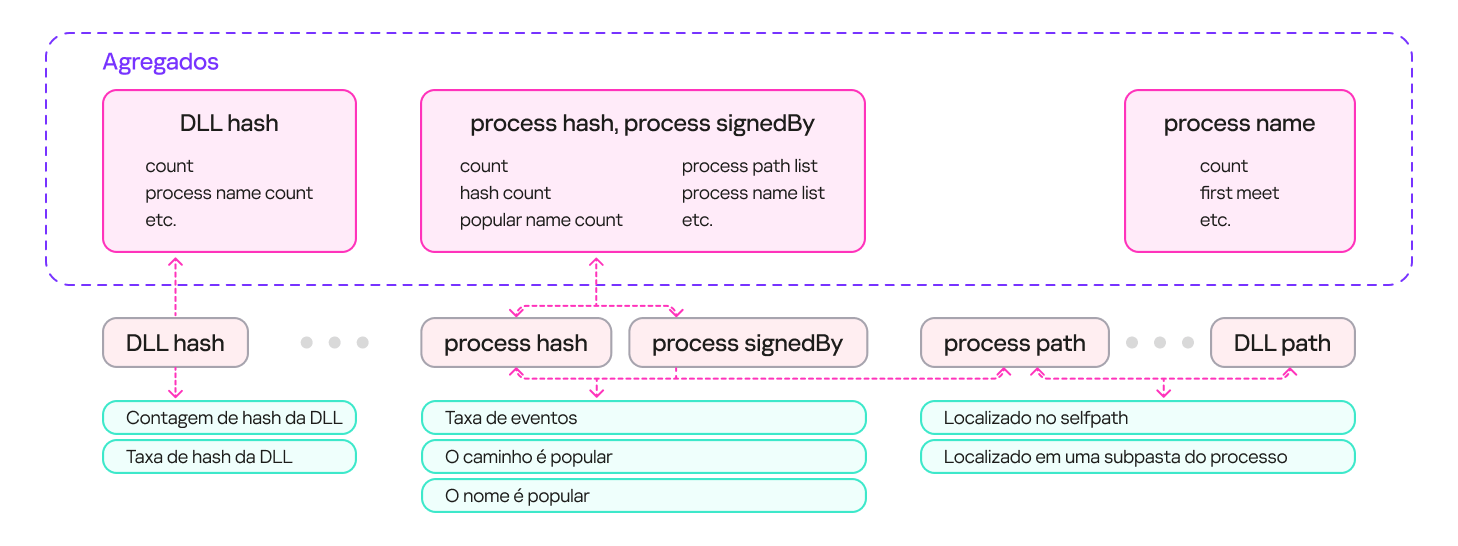
Extração de características de agregados
Carregamento de DLLs: como descrever o hijacking
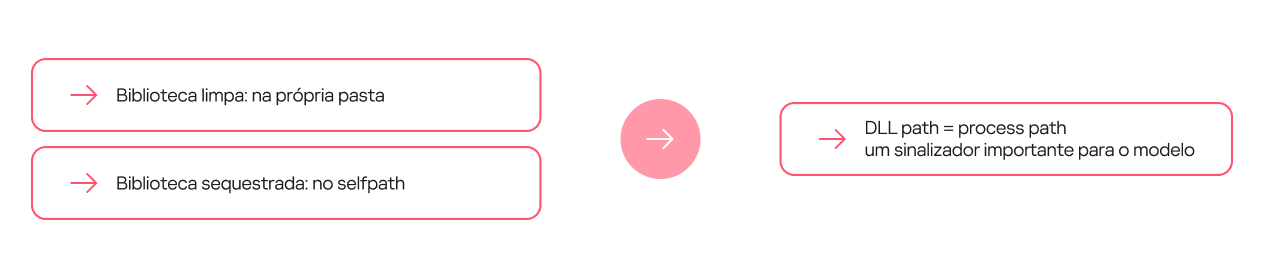
Certas combinações de características (dependências) são uma forte indicação de DLL hijacking. Estas podem ser dependências simples. Para alguns processos, a biblioteca limpa que os processos executam sempre fica localizada em uma pasta separada, enquanto a biblioteca maliciosa é quase sempre colocada na pasta do processo.
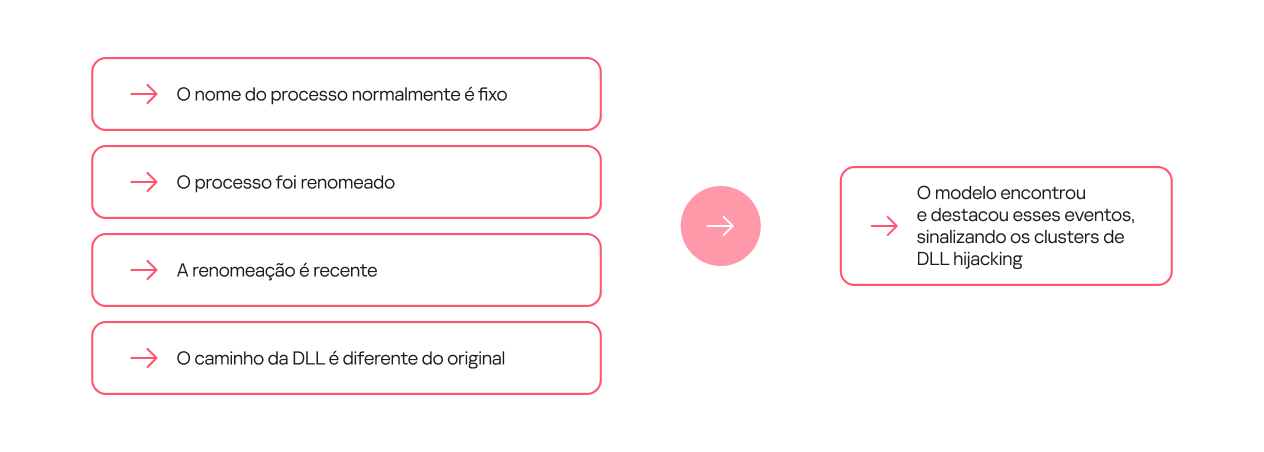
Outras dependências podem ser mais complexas e exigem que várias condições sejam atendidas. Por exemplo, que muda o seu próprio nome, não indica, por si só, um DLL hijacking. No entanto, se o novo nome aparecer no fluxo de dados pela primeira vez e a biblioteca estiver localizada em um caminho não padrão, é altamente provável que a biblioteca seja maliciosa.
Evolução do modelo
Neste projeto, treinamos várias gerações de modelos. O objetivo principal da primeira geração era demonstrar que o machine learning poderia, em teoria, ser aplicado à detecção de DLL hijacking. Ao treinar esse modelo, usamos a interpretação mais ampla possível do termo.
O fluxo de trabalho do modelo foi o mais simples possível:
- Utilizamos um fluxo de dados e extraímos uma descrição de frequência para conjuntos de chaves selecionados.
- Utilizamos o mesmo fluxo de dados de um período de tempo diferente e obtivemos um conjunto de características.
- Usamos a rotulagem do tipo 1, em que eventos nos quais um processo legítimo carregava uma biblioteca maliciosa de um conjunto específico de famílias foram classificados como DLL hijacking.
- Treinamos o modelo com base nos dados resultantes.
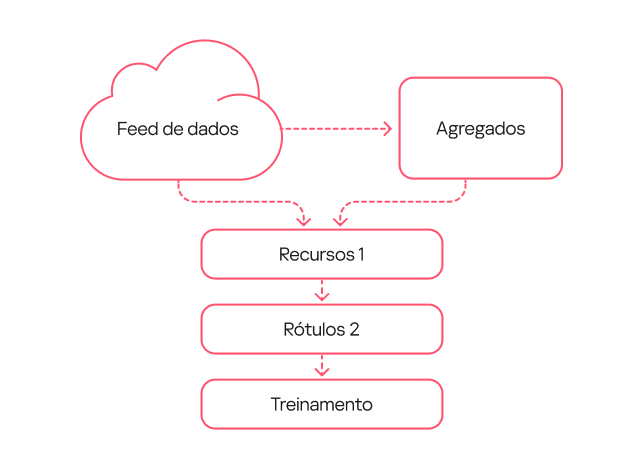
Diagrama do modelo de primeira geração
O modelo de segunda geração foi treinado com base em dados que foram processados pelo modelo de primeira geração e verificados por analistas (rotulagem do tipo 2). Em consequência, a rotulagem foi mais precisa do que durante o treinamento do primeiro modelo. Além disso, adicionamos mais características para descrever a estrutura da biblioteca e complicamos um pouco o fluxo de trabalho para descrever os carregamentos da biblioteca.
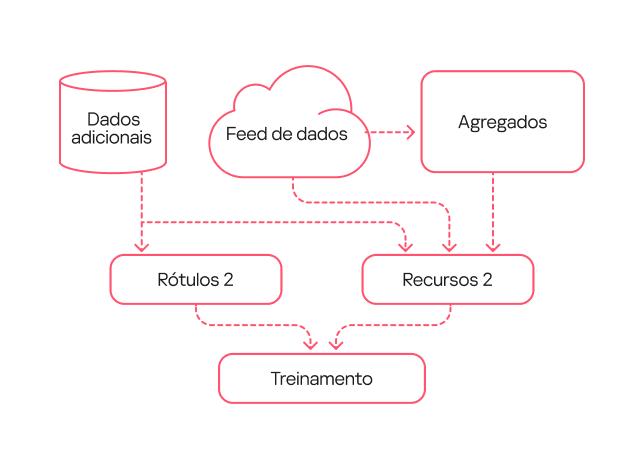
Diagrama do modelo de segunda geração
Com base nos resultados desse modelo de segunda geração, conseguimos identificar vários tipos comuns de falsos positivos. Por exemplo, a amostra de treinamento incluía aplicativos potencialmente indesejados. Em determinados contextos, eles podem apresentar comportamentos semelhantes ao DLL hijacking, mas não são maliciosos e raramente se enquadram nesse tipo de ataque.
Corrigimos esses erros no modelo de terceira geração. Primeiro, com a ajuda de analistas, sinalizamos os aplicativos potencialmente indesejados na amostra de treinamento para que não fossem detectados pelo modelo. Em segundo lugar, nesta nova versão, usamos uma rotulagem expandida que incluía detecções úteis da primeira e da segunda geração. Além disso, ampliamos a descrição das características por meio de one-hot encoding (uma técnica que converte atributos categóricos em formato binário) para determinados campos. E ainda, como o volume de eventos processados pelo modelo aumentou com o tempo, essa versão passou a incluir a normalização de todas as características com base no tamanho do fluxo de dados.
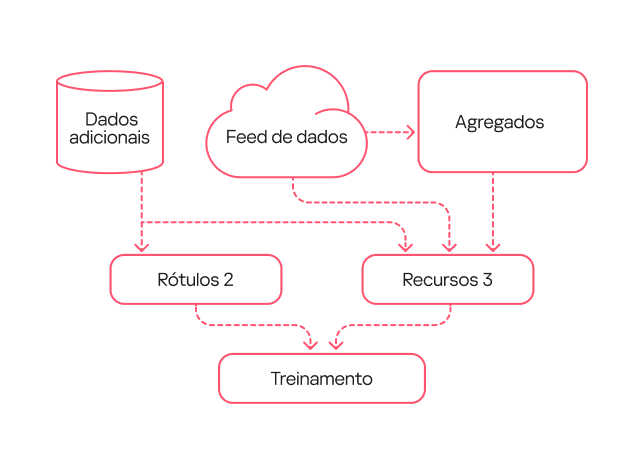
Diagrama do modelo de terceira geração
Comparação dos modelos
Para avaliar a evolução dos modelos, eles foram aplicados a um conjunto de dados novo. O gráfico apresenta a relação entre verdadeiros e falsos positivos por modelo.
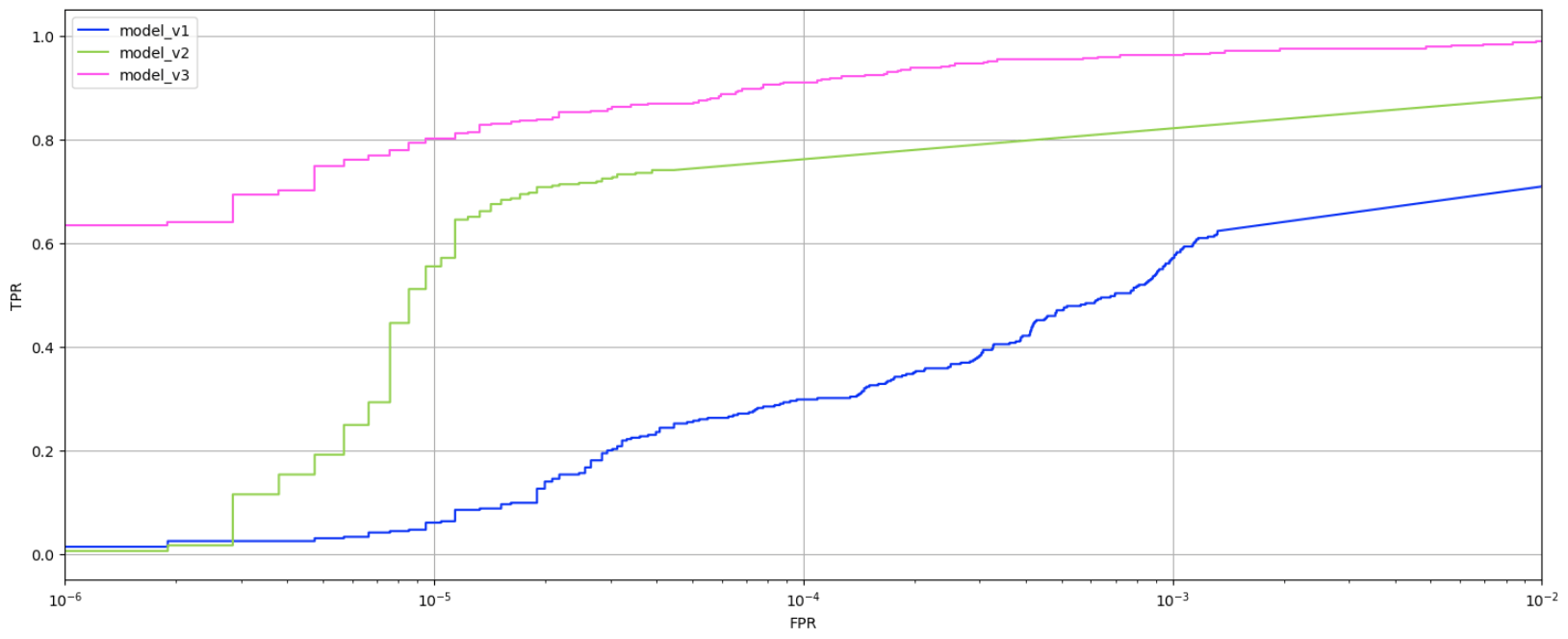
Tendências de verdadeiros positivos e falsos positivos dos modelos de primeira, segunda e terceira geração
À medida que os modelos evoluíram, a porcentagem de verdadeiros positivos cresceu. Enquanto o modelo de primeira geração alcançava um resultado relativamente bom (0,6 ou superior) apenas com uma taxa de falsos positivos muito alta (10⁻³ ou mais), o modelo de segunda geração atingiu esse resultado com uma taxa de 10⁻⁵. O modelo de terceira geração, que obteve a mesma taxa de falsos positivos baixa, produziu 0,8 positivos verdadeiros, o que é considerado um bom resultado.
Avaliar os modelos no fluxo de dados com uma pontuação fixa mostra que o número absoluto de novos eventos rotulados como DLL hijacking aumentou de uma geração para a seguinte. Dito isso, avaliar os modelos pela taxa de falsos positivos também ajuda a acompanhar o progresso: o primeiro modelo apresenta uma taxa de erro relativamente alta, enquanto as gerações segunda e terceira têm taxas significativamente menores.
Taxa de falsos positivos entre os dados de saída do modelo, de julho de 2024 a agosto de 2025 (download)
Aplicação prática dos modelos
As três gerações de modelos são usadas nos nossos sistemas internos para detectar casos prováveis de DLL hijacking dentro dos fluxos de dados de telemetria. Recebemos 6,5 milhões de eventos de segurança por dia, vinculados a 800 mil arquivos exclusivos. Os agregados são criados usando essa amostra em um intervalo especificado. Em seguida, são enriquecidos e inseridos nos modelos. Os dados de saída são, então, classificados por modelo e pela probabilidade de DLL hijacking atribuída ao evento, e depois são enviados aos nossos analistas. Por exemplo, se o modelo de terceira geração sinalizar um evento como DLL hijacking com alta confiança, ele deve ser investigado primeiro, enquanto um veredicto menos definitivo do modelo de primeira geração pode ser verificado por último.
Simultaneamente, os modelos são testados em um fluxo de dados separado que eles nunca viram antes. Isso é feito para avaliar sua eficácia ao longo do tempo, pois o desempenho da detecção de um modelo pode diminuir. O gráfico abaixo mostra que a porcentagem das detecções corretas varia um pouco ao longo do tempo. Mas, em média, os modelos detectam de 70 a 80% dos casos de DLL hijacking.
Tendências de detecção de DLL hijacking para os três modelos, de outubro de 2024 a setembro de 2025 (download)
Recentemente, implantamos um modelo de detecção de DLL hijacking no Kaspersky SIEM, mas, primeiramente, testamos o modelo no serviço Kaspersky MDR. Durante a fase piloto, o modelo ajudou a detectar e prevenir vários incidentes de DLL hijacking nos sistemas dos nossos clientes. Escrevemos um artigo explicando como o modelo de machine learning para detectar ataques direcionados envolvendo DLL hijacking funciona no Kaspersky SIEM e os incidentes identificados.
Conclusão
Com base no treinamento e na aplicação das três gerações de modelos, o experimento de detecção de DLL hijacking usando machine learning foi um sucesso. Fomos capazes de desenvolver um modelo que distingue eventos semelhantes a DLL hijacking de outros eventos, e o refinamos para um estado adequado para uso prático, não apenas nos nossos sistemas internos, mas também nos produtos comerciais. Atualmente, os modelos operam na nuvem, lendo centenas de milhares de arquivos exclusivos por mês e detectando milhares de arquivos usados em ataques de DLL hijacking a cada mês. Eles identificam regularmente variações desses ataques que antes eram desconhecidas. Os resultados dos modelos são enviados aos analistas, que os verificam e criam novas regras de detecção com base nas descobertas.
Autores
Na mesma categoria










Como treinamos um modelo de ML para detectar DLL hijacking